-

-
スパコン・高速化解析プログラムの高速化・高度化
解析プログラムの高速化・高度化
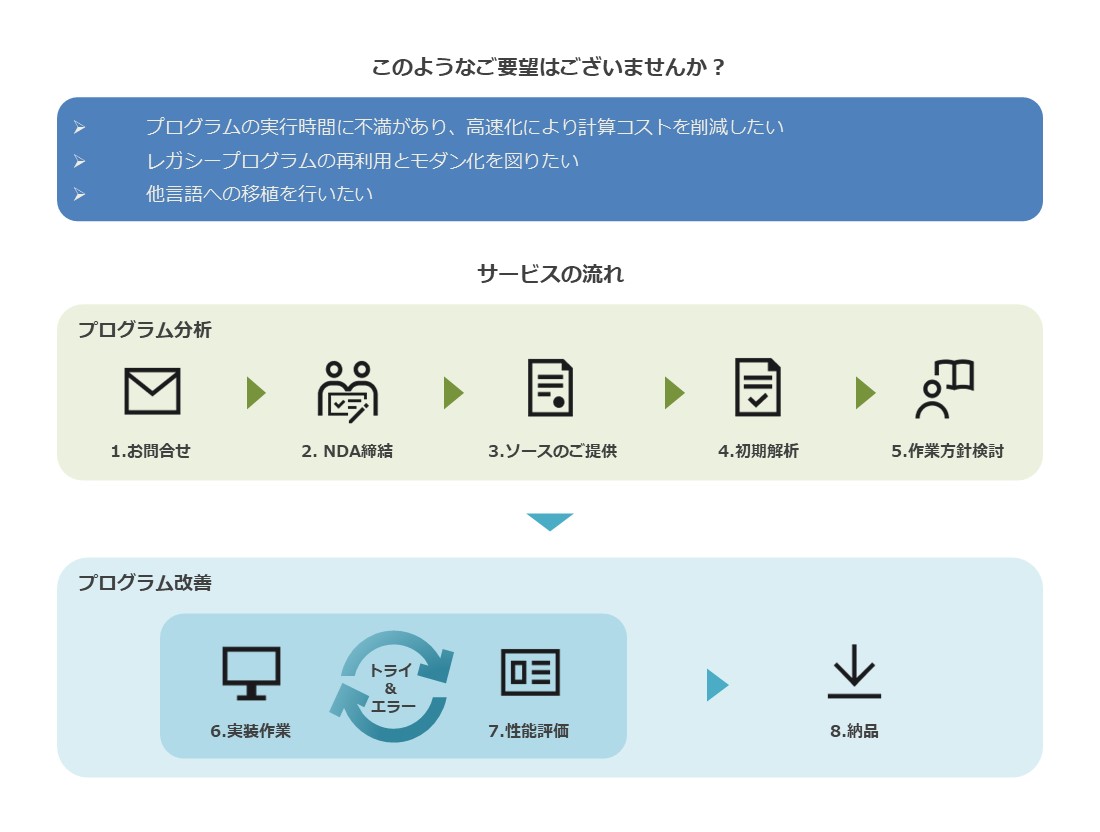
| 適用分野 および特徴 |
|
|---|---|
| 詳細 |
|
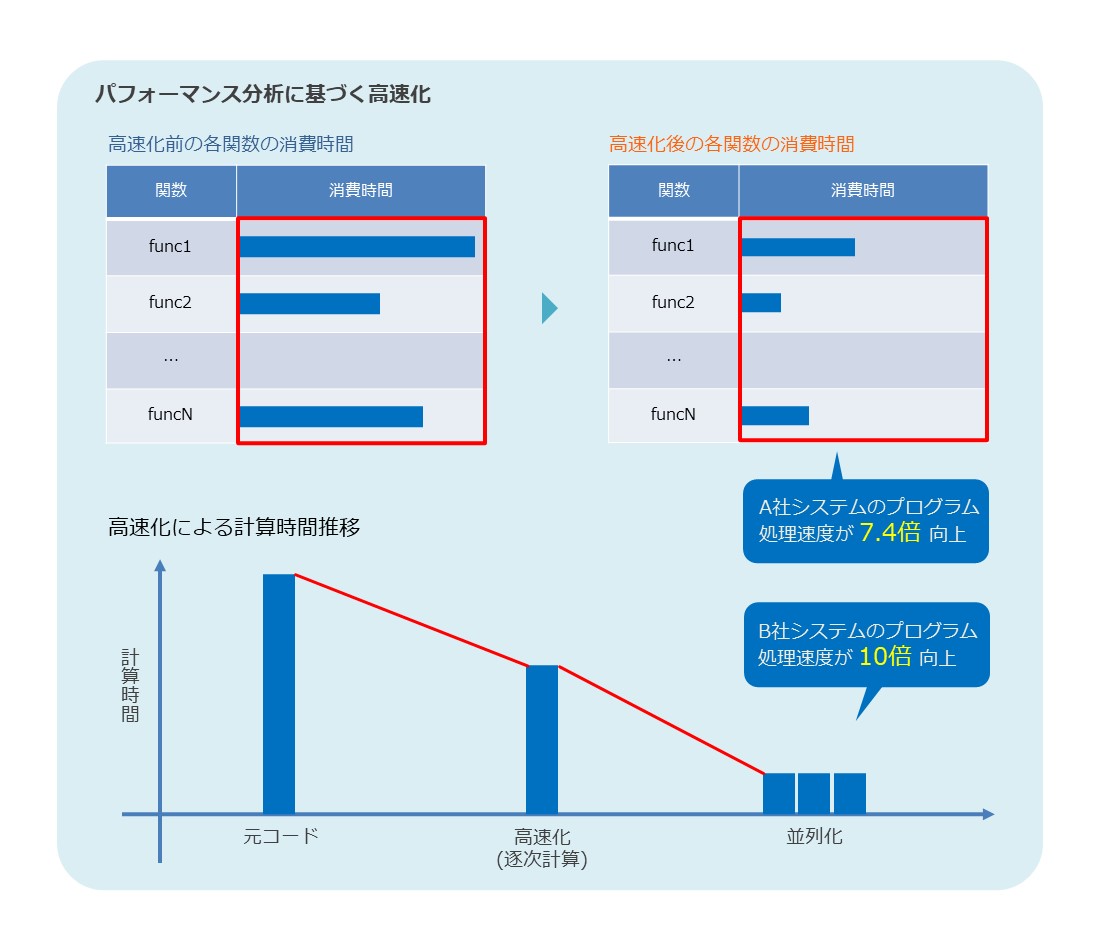
| 適用分野 および特徴 |
|
|---|---|
| 詳細 |
|
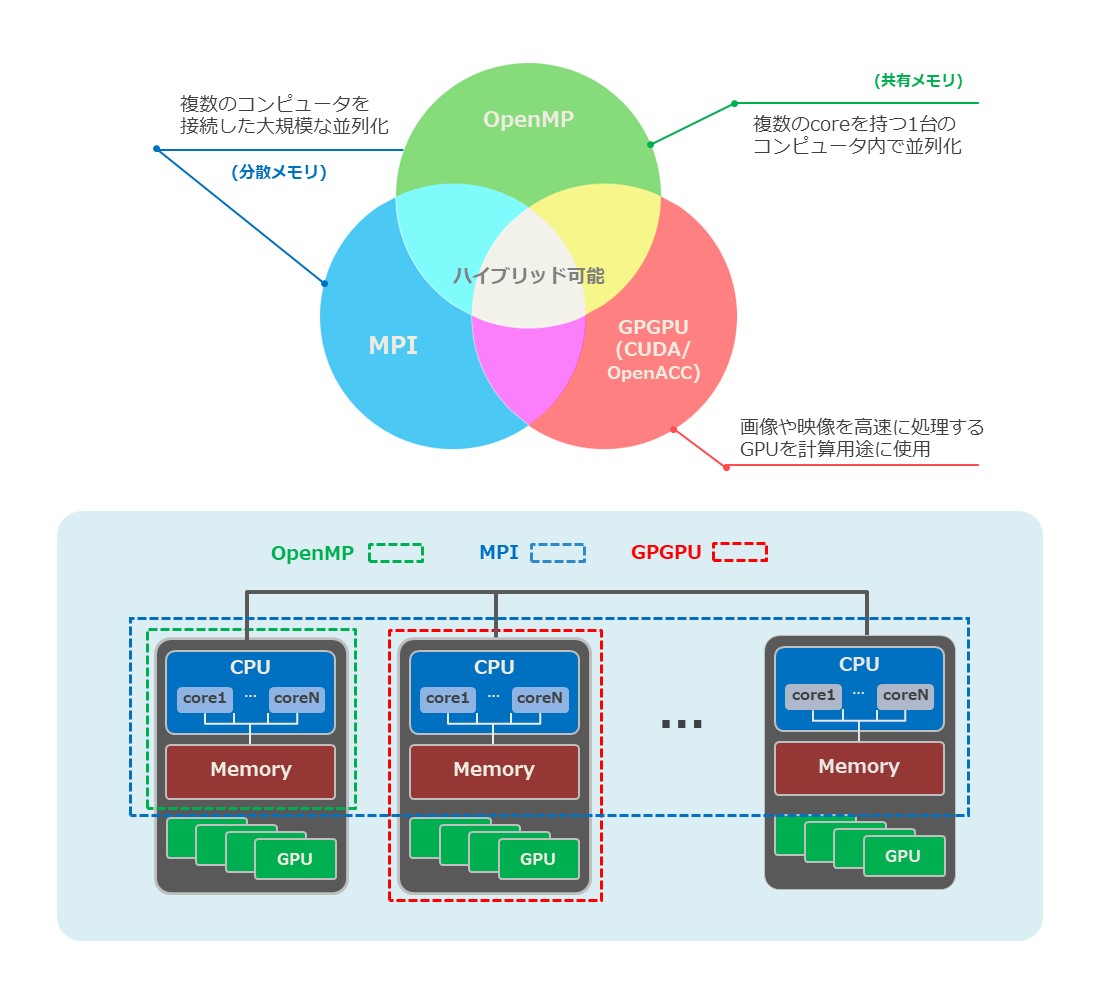
| 適用分野 および特徴 |
|
|---|---|
| 詳細 |
|
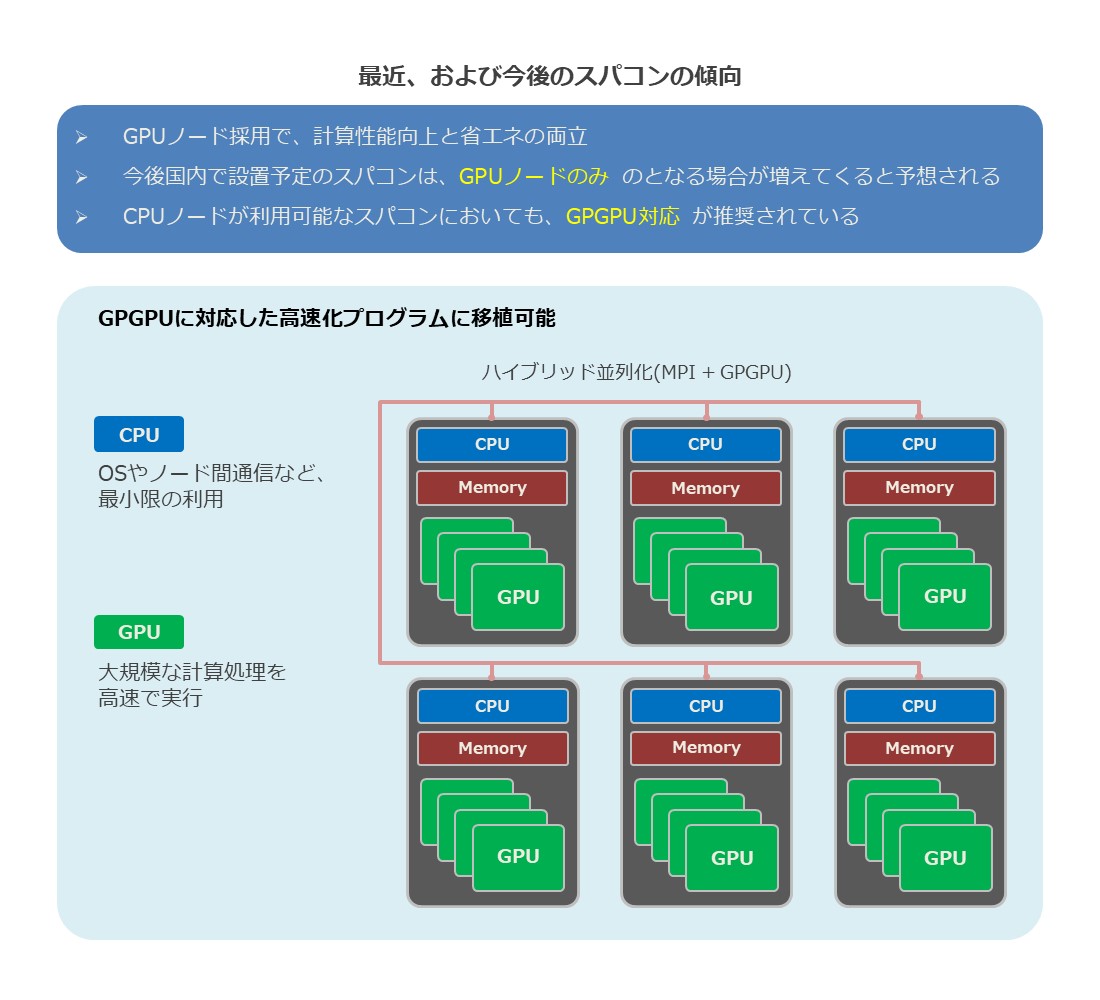
| 適用分野 および特徴 |
|
|---|---|
| 詳細 |
|














